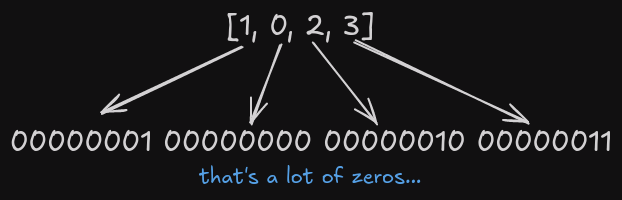
Efficient data retrieval is crucial for high performance applications. Whether
you're configuring a complex system or handling large datasets, the speed of
hash lookups can significantly impact performance. In this post, we'll explore
various methods to optimize hash lookups and benchmark their performance.
You can find my benchmarking code available here.
The Challenge
Let's say that you have a hash (aka
dictionary
aka
map
aka associative array;
something with key/value
pairs) representing configuration for your system.
At runtime, let's assume that your application only needs access to a small
number of these configuration items to handle a given request.
Let's also say that this hash can get pretty large; some users have very complex
configurations.
{
"setting_1": "value 1",
"setting_2": "value 2",
/* ... */
"setting_10000": "value 10000",
}
A common way of storing this configuration is in a
JSON file. JSON is really simple to use for this
type of problem. Just use something like JSON.parse to parse your file, and do a lookup
for whatever key you want:
config_data = File.read("config.json")
config = JSON.parse(config_data)
puts config["setting_500"]
# => "value 500"
Awesome, what's the problem?
Assuming that we just want to fetch a small number of items from this
configuration, there are a few problems here:
- We have to load the entire file into memory
- We then have to parse the entire file to get our hash object. This involves
inserting every item in configuration into a new hash object, which is an O(n) operation.
If our configuration is quite large, then the parsing & hash construction time
will be far greater than our lookup time.
$ ruby benchmark.rb -f json -s hash
Calculating -------------------------------------
load 829.185 (±30.0%) i/s (1.21 ms/i)
parse 24.779 (± 8.1%) i/s (40.36 ms/i)
get_key 4.242M (± 3.7%) i/s (235.72 ns/i)
load/parse/get_key 22.561 (± 8.9%) i/s (44.32 ms/i)
(I've removed some superfluous information from the output snippets here in the
interests of clarity; the number I'm paying attention to is the time per
iteration represented in the last column.)
Lookups into the hash, once created, are very fast: about 200ns per lookup.
However, for 100,000 entries, just parsing the data and creating the hash takes about
40ms on my system.
In fact, the hash construction time is the fundamental issue to overcome
when trying to speed up our overall time here. Simply creating a hash from the
data takes about 20ms on my system:
$ ruby benchmark-to_h.rb < output/array.json
Calculating -------------------------------------
to_h 37.764 (±18.5%) i/s (26.48 ms/i)
It makes sense when you think about it. Before we can get our hash object containing
our configuration, we need to iterate through each key/value pair and insert it
into the hash object. Only then can we do a lookup for the key we're interested
in.
How can we make this better?
A bunch of different ideas come to mind:
We can try different ways to encode the data. For example: using
MessagePack, protobufs,
or capnproto. Each of these use more efficient ways to
serialize/de-serialize the data, speeding up the parsing time.
Another idea is to encode our data as a sorted list of
key/value pairs instead of as a hash, and use a binary search to lookup the key
that we want.
Or, we can try and use perfect hashes; here we would encode
our data as a list of key/value pairs as above, but augmented with additional
information that makes it possible to treat the array as a pre-computed hash
table.
Other ideas: sqlite, dbm/lmdb. These benefit from encoding the index within the
file itself, so we don't need to reconstruct a hash table/index again when loading the data. Storing
more structured data in these is more challenging though, and lookups in these
types of data stores are typically O(log N) instead of O(1)
MessagePack
MessagePack is an easy thing to try first since it's almost a drop-in
replacement for JSON in our use case.
$ ruby benchmark.rb -f msgpack -s hash
Calculating -------------------------------------
load 679.466 (± 5.3%) i/s (1.47 ms/i)
parse 27.958 (± 3.6%) i/s (35.77 ms/i)
get_key 4.692M (± 3.4%) i/s (213.13 ns/i)
load/parse/get_key 27.031 (± 3.7%) i/s (36.99 ms/i)
Well, we've improved the parsing time by about about 5ms, which is a nice
improvement, but still pretty slow overall. Again, we have that large hash
construction time to overcome, which MessagePack doesn't help us with.
Protobufs
To experiment with Protobufs, I've created a simple definition using the native map type:
syntax = "proto3";
message PBHash {
map<string, string> data = 1;
}
The results here are surprising:
$ ruby benchmark.rb -f pb -s hash
Calculating -------------------------------------
load 1.311k (±35.9%) i/s (762.93 μs/i)
parse 21.496 (± 4.7%) i/s (46.52 ms/i) # !!
get_key 3.098M (± 3.2%) i/s (322.75 ns/i)
load/parse/get_key 20.707 (± 4.8%) i/s (48.29 ms/i)
It looks like parsing protobuf maps are significantly slower than parsing the
equivalent JSON or msgpack objects.
Encode as an array
Let's see what happens if we encode our data as an array.
This may improve parsing time, since we don't need to construct a large hash
object in memory. The trade-off is that lookup times become O(log n) instead of
O(1), assuming we can sort our input. As a first approximation, we can
compare times to load & parse the array.
Using JSON I see marginal improvement to load & parse the data (~30ms), but
using Protobufs we can load & parse the data in about 6ms. Unfortunately I
couldn't get good measurements for the full load/parse/get_key with protobufs;
it seems like doing a binary search for elements in the protobuf arrays is
relatively slow in Ruby. Fetching individual items is fast.
ruby -Iproto benchmark.rb -f pb -s array
Calculating -------------------------------------
load 1.641k (±10.7%) i/s (609.32 μs/i)
parse 163.886 (± 3.1%) i/s (6.10 ms/i)
get_key 27.325 (±11.0%) i/s (36.60 ms/i)
load/parse/get_key 3.000 (±33.3%) i/s (333.32 ms/i) # ???
Perfect hashes
Maybe we can get the best of both worlds by using a perfect
hash to order our data in
a particular way to make it cheap to find?
There are several ways of constructing a perfect hash; the
CHD algorithm is fairly easy to
implement (without the "compress" part of compress-hash-displace)
, and can compute a minimal perfect hash function in O(n) time.
The way it works is that we compute a secondary array of seeds that are used to
prevent collisions between keys in the data set. To find the index of an element
by its key, we compute:
# Find index for `key`
seed = seeds[hashfunc(seed: 0, data: key) % seeds.size]
index = hashfunc(seed: seed, data: key) % data.size]
value = data[index]
The results of using CHD with Protobufs are very good (using cityhash as the
hashing function):
$ ruby benchmark.rb -f pb -s chd
Calculating -------------------------------------
load 1.920k (± 7.0%) i/s (520.85 μs/i)
parse 173.076 (± 4.0%) i/s (5.78 ms/i)
get_key 491.510k (± 1.9%) i/s (2.03 μs/i)
load/parse/get_key 154.828 (± 1.9%) i/s (6.46 ms/i)
Summary
Wow, that was a lot! What did we learn?
Benchmarks are hard! I wouldn't take any results here as absolute proof that X
is better or worse than Y. Your data and use cases are most likely very different.
Using perfect hashes or binary search in an array of key/value pairs look like
they're much faster in general than simple lookups into a hash object. The time
to construct the hash object plays such a large part in the overall timings.
I'm surprised at the performance of protobufs in generally. They're much slower
than I expected, in everything except the perfect hash (CHD) case. It makes me
wonder if something is wrong with my implementation, or Ruby's protobuf
gem.
$ ruby benchmark-final.rb
Comparison:
load/parse/get_key pb chd: 124.3 i/s
load/parse/get_key msgpack array: 50.2 i/s - 2.48x slower
load/parse/get_key msgpack chd: 41.1 i/s - 3.02x slower
load/parse/get_key json array: 37.3 i/s - 3.33x slower
load/parse/get_key json chd: 27.9 i/s - 4.46x slower
load/parse/get_key msgpack hash: 23.8 i/s - 5.22x slower
load/parse/get_key json hash: 20.7 i/s - 6.00x slower
load/parse/get_key pb hash: 19.4 i/s - 6.40x slower
load/parse/get_key pb array: 3.1 i/s - 40.07x slower
To follow up, I'd like to explore using capnproto,
and running similar benchmarks in other languages to see if the protobuf
performance improves.