Dealing with bursty load
John has been doing a regular series of posts about load on our infrastructure, going back years. Recently, GPS also posted about infrastructure efficiency here. What I've always found interesting is the bursty nature of the load at different times throughout the day, so thought people might find the following data useful.
Every time a developer checks in code, we schedule a huge number of build and test jobs. Right now on mozilla-central every checkin generates just over 10 CPU days worth of work. How many jobs do we end up running over the course of the day? How much time to they take to run?
I created a few graphs to explore these questions - these get refreshed hourly, so should serve as a good dashboard to monitor recent load on an ongoing basis.
# of jobs running over time
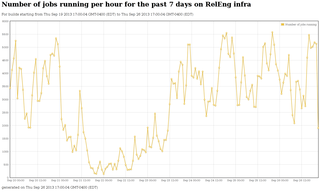 This shows how many jobs are running at any given hour over the past 7 days
This shows how many jobs are running at any given hour over the past 7 days
# of cpu hours run over time
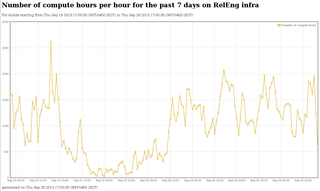 This shows how many CPU hours were spent for jobs that started for any
given hour over the same time period.
This shows how many CPU hours were spent for jobs that started for any
given hour over the same time period.
A few observations about the range in the load:
- Weekends can be really quiet! Our peak weekday load is about 20x the lowest weekend load.
- Weekday load varies by about 2x within any given day.
Over the years RelEng have scaled our capacity to meet peak demand. After all, we're trying to give the best experience to developers; making people wait for builds or tests to start is frustrating and can also really impact the productivity of our development teams, and ultimately the quality of Firefox/Fennec/B2G.
Scaling physical capacity takes a lot of time and advance planning. Unfortunately this means that many of our physical machines are idle for non-peak times, since there isn't any work to do. We've been able to make use of some of this idle time by doing things like run fuzzing jobs for our security team.
Scaling quickly for peak load is something that Amazon is great for, and we've been taking advantage of scaling build/test capacity in EC2 for nearly a year. We've been able to move a significant amount of our Linux build and test infrastructure to run inside Amazon's EC2 infrastructure. This means we can start machines in response to increasing load, and shut them down when they're not needed. (Aside - not all of our reporting tools know about this, which can cause some reporting confusion because it appears as if the slaves are broken or not taking work when in reality they're shut off because of low demand - we're working on fixing that up!)
Hopefully this data and these dashboards help give some context about why our infrastructure isn't always 100% busy 100% of the time.
Comments